Finetuning DeepSeek-R1 for Medical Reasoning Using QLoRA (Quantized Low-Rank Adaptation)
𝐅𝐢𝐧𝐞𝐭𝐮𝐧𝐢𝐧𝐠 𝐚 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐋𝐋𝐌 𝐬𝐩𝐞𝐜𝐢𝐟𝐢𝐜𝐚𝐥𝐥𝐲 𝐟𝐨𝐫 𝐦𝐞𝐝𝐢𝐜𝐚𝐥 𝐪𝐮𝐞𝐫𝐢𝐞𝐬. This helped me understand finetuning at deep level and gave practical insight into how domain-adapted models can significantly outperform general-purpose LLMs.
𝐅𝐢𝐧𝐞𝐭𝐮𝐧𝐢𝐧𝐠 𝐃𝐞𝐞𝐩𝐒𝐞𝐞𝐤-𝐑1 𝐟𝐨𝐫 𝐌𝐞𝐝𝐢𝐜𝐚𝐥 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐔𝐬𝐢𝐧𝐠 𝐐𝐋𝐨𝐑𝐀 (𝗤𝘂𝗮𝗻𝘁𝗶𝘇𝗲𝗱 𝗟𝗼𝘄-𝗥𝗮𝗻𝗸 𝗔𝗱𝗮𝗽𝘁𝗮𝘁𝗶𝗼𝗻)
Recently completed a research task that I’ve been deeply interested in, 𝐅𝐢𝐧𝐞𝐭𝐮𝐧𝐢𝐧𝐠 𝐚 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐋𝐋𝐌 𝐬𝐩𝐞𝐜𝐢𝐟𝐢𝐜𝐚𝐥𝐥𝐲 𝐟𝐨𝐫 𝐦𝐞𝐝𝐢𝐜𝐚𝐥 𝐪𝐮𝐞𝐫𝐢𝐞𝐬. This helped me understand finetuning at deep level and gave practical insight into how domain-adapted models can significantly outperform general-purpose LLMs.
🔗𝐂𝐡𝐞𝐜𝐤 𝐨𝐮𝐭 𝐆𝐢𝐭𝐇𝐮𝐛 𝐑𝐞𝐩𝐨:
https://github.com/Aliyan-12/deepseek-r1-finetuning-using-qlora-for-medical-reasoning---colab
𝐏𝐫𝐢𝐦𝐚𝐫𝐲 𝐎𝐛𝐣𝐞𝐜𝐭𝐢𝐯𝐞:
The primary objective was to make DeepSeek-R1 reasoning more structured, logical, and clinically aligned using the dataset providing medical questions, chain-of-thought reasoning, and final responses.
𝐌𝐞𝐭𝐡𝐨𝐝𝐨𝐥𝐨𝐠𝐲:
• Unsloth for efficient and fast training.
• QLoRA to train lightweight adapters.
• HuggingFace TRL SFTTrainer for supervised finetuning.
• A high-quality medical reasoning dataset (FreedomIntelligence/medical-o1-reasoning-SFT).
𝐅𝐢𝐧𝐞𝐭𝐮𝐧𝐢𝐧𝐠 𝐀𝐝𝐯𝐚𝐧𝐭𝐚𝐠𝐞𝐬:
Finetuning is one of the most impactful ways to push LLMs into becoming true domain experts. 𝐋𝐚𝐫𝐠𝐞 𝐦𝐨𝐝𝐞𝐥𝐬 𝐚𝐫𝐞 𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐚𝐬 𝐠𝐞𝐧𝐞𝐫𝐚𝐥𝐢𝐬𝐭𝐬. They know broad information, but need finetuning for specialized reasoning on clinical or financial domains.
𝐈𝐦𝐩𝐥𝐞𝐦𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧 𝐏𝐢𝐩𝐞𝐥𝐢𝐧𝐞:
• 𝐋𝐨𝐚𝐝𝐞𝐝 𝐃𝐞𝐞𝐩𝐒𝐞𝐞𝐤-𝐑1 𝐮𝐬𝐢𝐧𝐠 𝐔𝐧𝐬𝐥𝐨𝐭𝐡: Reduced VRAM usage and speed up training ideal for Colab.
• 𝐀𝐩𝐩𝐥𝐢𝐞𝐝 𝐐𝐋𝐨𝐑𝐀 𝐚𝐝𝐚𝐩𝐭𝐞𝐫𝐬: Only low-rank adapter weights were trained, keeping the process lightweight.
• 𝐔𝐬𝐞𝐝 𝐒𝐅𝐓 𝐓𝐫𝐚𝐢𝐧𝐞𝐫: Used Supervised Finetuning with training arguments including batch size, optimizer, learning rate, and training epochs.
• 𝐒𝐚𝐯𝐞𝐝 𝐭𝐡𝐞 𝐟𝐢𝐧𝐞𝐭𝐮𝐧𝐞𝐝 𝐚𝐝𝐚𝐩𝐭𝐞𝐫: Saved the adapter locally which made the finetuned checkpoint easy to load and share.
• 𝐕𝐚𝐥𝐢𝐝𝐚𝐭𝐞𝐝 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞: The model now handles complex medical questions with improved structure and reasoning.
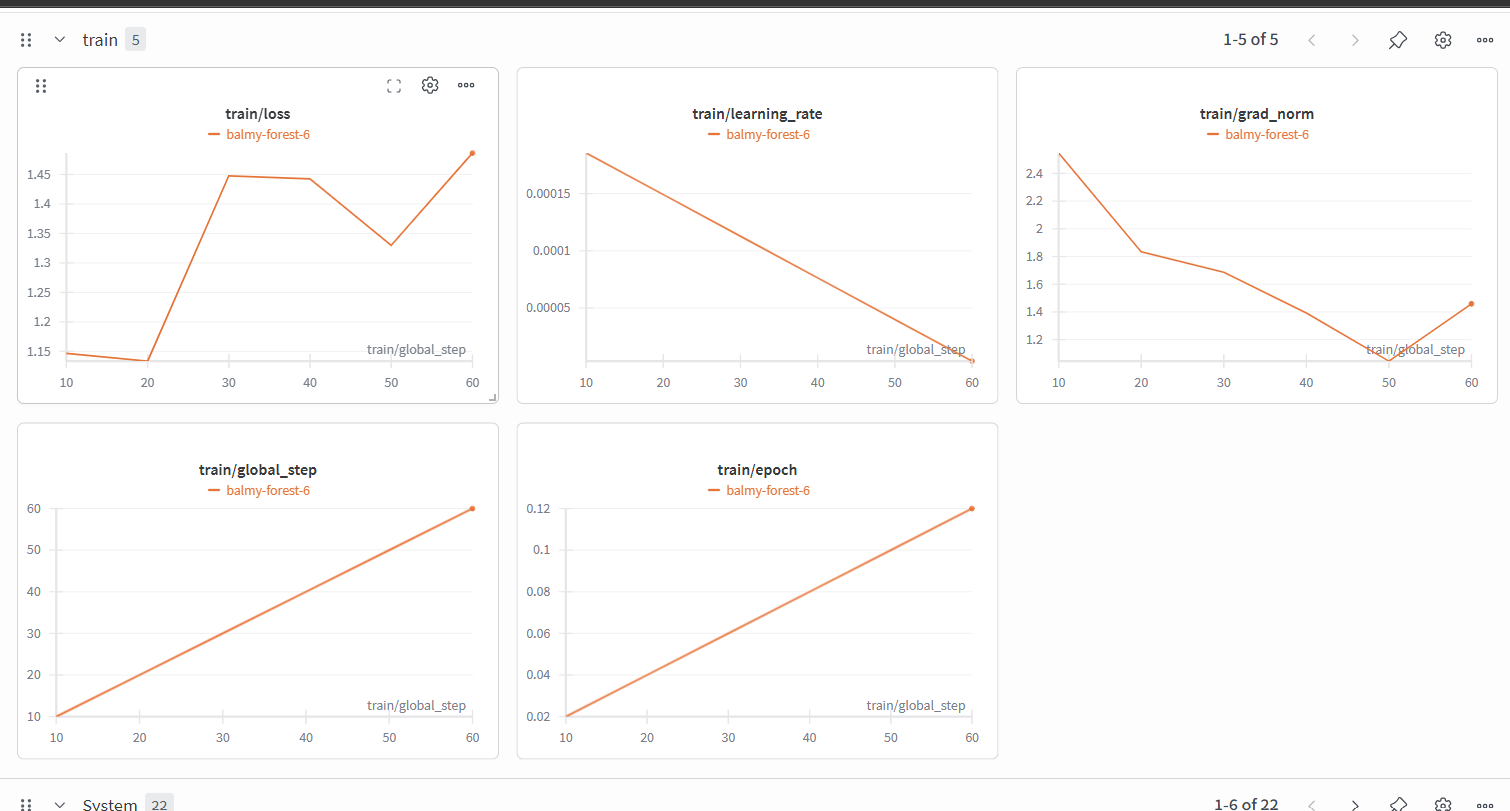
𝐑𝐞𝐬𝐮𝐥𝐭𝐬 & 𝐌𝐞𝐭𝐫𝐢𝐜𝐬:
• 𝐋𝐨𝐬𝐬 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧: The 𝐭𝐫𝐚𝐢𝐧/𝐥𝐨𝐬𝐬 graph shows an initial spike before a downward trend toward step 50, the final uptick suggests the model was starting to get more complex medical tokens.
• 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐑𝐚𝐭𝐞 𝐒𝐜𝐡𝐞𝐝𝐮𝐥𝐞: The 𝐭𝐫𝐚𝐢𝐧/𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠_𝐫𝐚𝐭𝐞 shows linear decay strategy was utilized, starting from a peak near 0.002 and reducing down to 0, ensuring stable weight updates.
• 𝐆𝐫𝐚𝐝𝐢𝐞𝐧𝐭 𝐒𝐭𝐚𝐛𝐢𝐥𝐢𝐭𝐲: The 𝐭𝐫𝐚𝐢𝐧/𝐠𝐫𝐚𝐝_𝐧𝐨𝐫𝐦 shows a healthy stabilization after step 20, indicating that the QLoRA adapters were effectively capturing the medical dataset without exploding gradients.
---
Feel free to explore, fork, or ask questions — Happy to answer thoughts on LLM finetuning.